
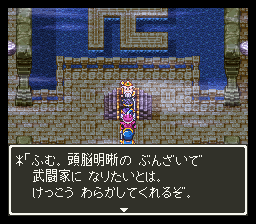
- 固定文字列(2バイト)の定義
- 固定文字列(1バイト)→固定文字列(2バイト)への変換処理

1は意外と大掛かりな作業になります。もともと存在していない可変長のデータを定義し、かつ既存の固定文字列(1バイト)のように変更できるようにしないと手間がかかってしょうがなくなるので、これはSFCGENEditorのDQ3プラグインを変えてそういう可変長のデータを変更できるようにする必要があります。正直この手の独自の変更をプラグインに入れるのは気持ちのいいものではないのですが、「必要ない人には関係ない」話なので割り切ることにしました。
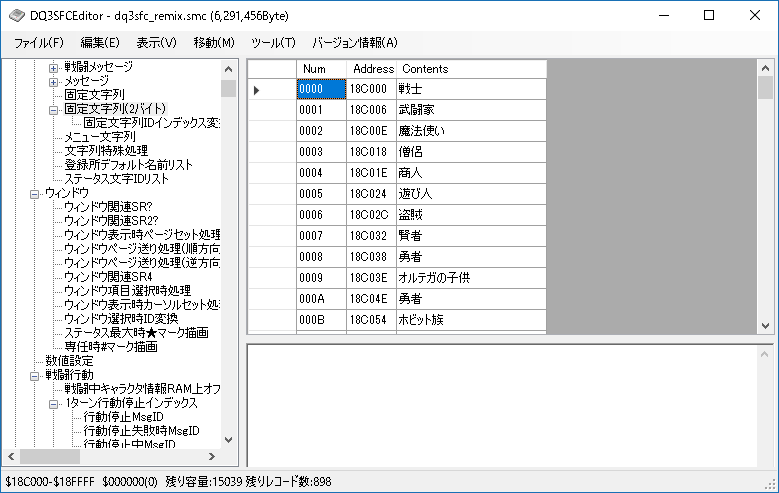
はるか昔に作った固定文字列のデコード、編集機能をパクって使う文字列を2バイト文字に変えるだけなので思ったほど手間はかかりませんでした。実装後ある程度固定文字列を追加してからバグが見つかったのはご愛嬌。
次に2ですが、現状想定している変換対象の文字は職業名(16) + フロア名(約50) + 性格名(約30)+ アイテム名(最大300?) で512レコードあれば十分というところです。通常は「固定文字列(1バイト)デコード→1文字ずつ2バイト文字(ひらがな)に変換して表示」という処理を「固定文字列(1バイト)ID を 変換テーブルを見て固定文字列(2バイト)IDに変換 → 固定文字列(2バイト)デコード→そのまま表示」という処理に変えることになります。この「固定文字列(1バイト)ID を 固定文字列(2バイト)IDに変換」するという処理がどれだけ重い処理なのかわからなかったので(変換テーブルにヒットしない場合毎回最大512レコードを空サーチする羽目になる)おっかなびっくり実装してみましたが、毎回512レコードサーチさせても表示時につっかかるように感じることもなく、結局杞憂だということがわかりました。当初アイテム名まで対象にすると各キャラクターの持ち物の表記とメッセージの表記が異なるケースが頻繁に発生する(「やくそう」→「薬草」など)ので対象外としていましたが、一部のイベントアイテムなど(变化のつえ、英雄指南6など)だけ2バイト文字を使うということにしました。現状トータル100レコードくらい変換テーブルにあるという状態です。
また、メッセージ中に出てくる固定文字列を意味する[B2]、アイテム名を意味する[B5]、[C7]は戦闘中でも使うため([C7]は不明)、余計なバグを防ぐということで新たに[D7]を固定文字列(2バイト)用に、[DE],[DF]をアイテム名(2バイト)用に使うことにします。当然メッセージ中で使用されている[B2],[B5],[C7]は適宜[D7],[DE][DF]に書き換える必要があります。
その他、当然[D7],[DE],[DF]に相当するデコード処理を実装する必要があります。
- SR:$01EA36 特殊文字処理[D7](1バイト固定文字列->2バイト固定文字列変換対応)(新SR)
| $01EA36 | JSR $B998 | SR: $01B998 | $BE59に$FFFFをセット |
|---|---|---|---|
| $01EA39 | LDA $BE77 | A=$BE77 | |
| $01EA3C | JSL $C1EA06 | SR: $01EA06 | 固定文字列ID2バイト変換(未変換c=off) |
| $01EA40 | BCS #$05 | if(c==on) goto $01EA47 | |
| $01EA42 | JSL $C1B75C | SR: $01B75C | 文字列特殊処理_SR_0007 ([B2]固定文字列ID) |
| $01EA46 | RTL | return | |
| $01EA47 | STZ $BDFB | $BDFB=#$00 | |
| $01EA4A | LDX #$0000 | X=#$0000 | |
| $01EA4D | JSL $C1E99B | SR: $01E99B | 固定文字列(2バイト)先頭位置取得 |
| $01EA51 | JSL $C1EA01 | SR: $01EA01 | 固定文字列(2バイト)デコード |
| $01EA55 | STA $BDFD,X | $BDFD+X=A | |
| $01EA58 | CMP #$00AC | A==#$00AC? | |
| $01EA5B | BEQ #$04 | if(z==on) goto $01EA61 | |
| $01EA5D | INX | X++ | |
| $01EA5E | INX | X++ | |
| $01EA5F | BRA #$F0 | goto $01EA51 | |
| $01EA61 | LDA #$00AB | A=#$00AB | |
| $01EA64 | STA $BDFD,X | $BDFD+X=A | デコードした文字を別バッファに保存 |
| $01EA67 | LDA #$0003 | A=#$0003 | 別バッファを使用+2バイト文字に変換済みフラグをON |
| $01EA6A | STA $BDF5 | $BDF5=A | |
| $01EA6D | RTL | return |
変換テーブルを見て変換対象が見つかれば固定文字列(2バイト)デコード処理をして見つからなければ通常の固定文字列(1バイト)デコード処理をするということをしています。変換テーブルは1レコード4バイトで変換対象の固定文字列ID(1バイト)と変換後の固定文字列ID(2バイト)を並べるだけの簡単なテーブルです。また、ここでの処理のキモは$BDF5に$01ではなく$03をセットすることです。オリジナルでは$01しか想定していませんが、この領域をビットフラグ扱いして、2ビット目を「2バイト文字に変換済み」という意味にすることで実際に画面に文字を表示する時に処理を切り替えられます。
- SR:$01EA06 固定文字列ID2バイト変換(未変換c=off)(新SR)
| $01EA06 | PHA | Push A | |
|---|---|---|---|
| $01EA07 | PHX | Push X | |
| $01EA08 | LDX #$0000 | X=#$0000 | |
| $01EA0B | LDA $D8B740,X | A=$18B740+X | 変換元の固定文字列(1バイト)ID |
| $01EA0F | CMP #$FFFF | A==#$FFFF? | #$FFFFなら検索終了 |
| $01EA12 | BEQ #$1A | if(z==on) goto $01EA2E | |
| $01EA14 | CMP $03,S | A==Stack($03)? | |
| $01EA16 | BNE #$0D | if(z==off) goto $01EA25 | |
| $01EA18 | LDA $D8B742,X | A=$18B742+X | |
| $01EA1C | CMP #$FFFF | A==#$FFFF? | 変換対象レコードが見つかっても変換後のIDが#$FFFFなら変換しない |
| $01EA1F | BEQ #$0D | if(z==on) goto $01EA2E | |
| $01EA21 | STA $03,S | Stack($03)=A | |
| $01EA23 | BRA #$0D | goto $01EA32 | |
| $01EA25 | INX | X++ | |
| $01EA26 | INX | X++ | |
| $01EA27 | INX | X++ | |
| $01EA28 | INX | X++ | |
| $01EA29 | CPX #$07FC | X>=#$07FC? | |
| $01EA2C | BCC #$DD | if(c==off) goto $01EA0B | |
| $01EA2E | PLX | Pull X | |
| $01EA2F | PLA | Pull A | |
| $01EA30 | CLC | c=off | |
| $01EA31 | RTL | return | |
| $01EA32 | PLX | Pull X | |
| $01EA33 | PLA | Pull A | |
| $01EA34 | SEC | c=on | |
| $01EA35 | RTL | return |
- SR:$01E99B 固定文字列(2バイト)先頭位置取得(新SR)(省略)
- SR:$01EA01 固定文字列(2バイト)デコード(新SR)(省略)
毎回512レコード分検索するのは意味が無いので#$FFFFのレコードが出てきたら終了としています。また、変換後の値が#$FFFFの場合も変換しないというようにしておきます。これにより「2バイト文字で表現するつもりだったがやっぱりやめる」というようなことが容易に実現できるようにしておきます。
これで2バイト文字がデコードできたので画面に表示する際に細工をして終わりです。
- SR:$01B024 1バイト文字を2バイト文字に変換
| 略 | |||
|---|---|---|---|
| $01B037 | JSR $EA6E | SR: $01EA6E | 固定文字列をバッファから返す |
| 略 |
- SR:$01EA6E 固定文字列をバッファから返す
| $01EA6E | PHA | Push A | |
|---|---|---|---|
| $01EA6F | LDA $BDF5 | A=$BDF5 | |
| $01EA72 | AND #$0002 | A&=#$0002 | 変換する必要があるかをチェック |
| $01EA75 | BEQ #$02 | if(z==on) goto $01EA79 | |
| $01EA77 | PLA | Pull A | |
| $01EA78 | RTS | return | |
| $01EA79 | PLA | Pull A | |
| $01EA7A | JSR $B078 | SR: $01B078 | 1バイト文字を2バイト文字に変換 |
| $01EA7D | RTS | return |
固定文字列が1バイト文字で展開されている場合はここで2バイト文字のひらがなに変換する必要がありますが、すでに2バイト文字(漢字)に変換済みの場合は余計な処理をする必要が無いので別バッファの文字をそのまませばいいだけになります。
アイテム名についても同様で、アイテムIDから固定文字列IDを取得した後、同様の変換処理をかませばいいということになります。
- SR:$01EA87 特殊文字処理[DE](アイテム名2バイト化対応)(新SR)
| $01EA87 | JSR $B998 | SR: $01B998 | $BE59に$FFFFをセット |
|---|---|---|---|
| $01EA8A | LDA $BE79 | A=$BE79 | |
| $01EA8D | JSL $C44E32 | SR: $044E32 引数:1#$FF 引数:2#$FF | アイテム名称ID取得 |
| $01EA93 | JSL $C1EA06 | SR: $01EA06 | |
| $01EA97 | BCS #$03 | if(c==on) goto $01EA9C | |
| $01EA99 | JMP $B762 ($01B762) | goto $01B762 | 文字列特殊処理_SR_0007 ([B2]固定文字列ID)の途中にジャンプ |
| $01EA9C | JMP $EA47 ($01EA47) | goto $01EA47 | 特殊文字処理[D7](1バイト固定文字列->2バイト固定文字列変換対応)の途中にジャンプ |
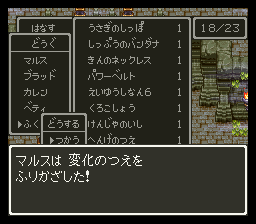
ということで一通りの作業が終わりました。枠組みは作ったので個人的な悩みどころは「アイテムをどこまで2バイト文字を使って表現するか」になりました。真面目にやるとキリがないので主にイベントでしか出番のないアイテム(入手時と使用時くらいしか出番がないようなもの)や、個人的な好みで「これは漢字で表記したい」というアイテムを中心に漢字を使っています。あまりやりすぎると「どうぐ」メニューでの表記とメッセージでの表記の乖離が大きくなるので程々にしたいところです。

コメント
「変換元の固定文字列 ID」がレコード配列 $D8B740 中で一意であるのならば、レコードを「変換元の固定文字列 ID」でソートしておけば、探索のアルゴリズムに線形探索ではなく二分探索が採用できて、最悪 512 回の比較が最悪 10 回の比較に抑えられませんか。
TAX, TXA, ASL, LSR 各命令を駆使したコードになると思います。
身もふたもないことを言ってしまうと、一番処理時間がかかると思われる「ヒットしない512レコード全回しでも処理速度に違和感は覚えなかった」のが2分検索法などを使わなかった最大の理由です(実際はヒットしないケースでも#$FFFFが出てくると途中で検索をやめるので一番時間が掛かるケースでもトータルの処理量は現状約110レコード分のループです)。2分検索法の前提となる「全IDをソート」は変換不要のレコードまで含めておく必要がある、追加の必要がある時にソートしなおす必要がある、管理が煩雑になる(?)等いろいろ面倒になりそうなので見送っています。他には各項目(職業名、地名、アイテム名)のインデックスに対応する固定文字列(2バイト)用の配列を別個で用意して固定文字列ID(1バイト)ではなく必要に応じて固定文字列ID(2バイト)のほうを参照させる(512レコードサーチのような馬鹿げた処理はいらないが、各所に変換処理を書く必要があるので対応が面倒)、各項目ごとにの変換テーブル中の検索対象のインデックス範囲を指定するなど考えていましたが杞憂だったということで全部ボツにしています。
そのうち出す現物で動作を見てみてください。